为什么监控?
整个系统, 按照服务拆分, 提高内部服务的可见性. 第一时间发现问题苗头. 从系统外缘监控是不够的, 需要在系统内部继续拆分监控. 监控的重要性不用赘述, 其难度也是不低. 对于一个HTTP API 响应慢这个事实不能帮助我们定位到低慢在哪里. 对于一个请求的响应处理过程中的重要环节, 从响应时间到失败率, 都需要加以监控. 此外, 细化到模块的监控, 也可以帮助我们快速定位系统瓶颈.
监控系统, 从组成部分来分:
- 采集上报
- 数据存储
- 展示面板
- 告警机制
从监控指标来分
- 通用的监控
- 服务器层面: 内存占用, CPU负载, 网络带宽, 磁盘占用, 等
- HTTP API 层面: QPS, Latency, 状态码分类, 等
- 数据存储服务监控: 连接数, 查询延迟, 等
- 业务层面的数据, 如每个地区的点击量等
总览
- Ganglia, Nagios, Zabbix 等, 偏传统运维部门使用的工具
- Graphite
- InfluxDB
- Prometheus
- OpenTSDB
- ELK 栈, 或者是 L (Logstash) 替换成F (Flume)
- Sentry 跟多偏向后台错误日志告警场景
- SaaS 服务
- DataDog
- Dataloop
- Mackerel
- Cloudinsight 国内团队
- 技术架构, 看上去是用 OpenTSDB 存储, Riemann(http://riemann.io/) 进行实时数据处理和告警
- 数据格式和StatsD类似
日志, 还是监控数据 ???
日志 / logs: 最详细的数据
监控指标 / metrics: 汇总之后的数据
监控指标 + 设计良好的图表, 可以帮助我们很快的定位问题.
日志, 基于等级的告警, 类似 sentry 服务, 只能挑重要的记录, 如错误, 警告等. 一个性能要求高的接口服务, 是不可能把每个请求的详细信息全部记录下来的, 系统负担太大.
经常对于日志的某些结构化的字段, 进行汇总告警, 比如说 警告数过多等 汇总后的数据我们也可以理解为日志的监控指标.
监控指标细分:
- counter: 计数器, 一段时间窗口内的请求数, IO等
- gauge: 监控值(??? 如何翻译), 是指观察时刻这一点的某个度量指标, 如内存占用, 线程数等等
- histogram: 它的意义是很重要的, 如基于counter我们只能统计平均值, 而中所周知, 平均值是骗人的, 我们更关心的是P99值, 即99%的请求延迟小于多少. 这种统计一般开销太大, 实际统计中采用近似方法, 而且没法对多个时间窗口统计的数据进行聚合, 所以目前实际使用场景不多.
Ganglia
传统运维使用的工具.
Ganglia 面板使用直观感受: 界面太丑陋, 使用起来不够直观方便.
底层使用了 RRD 作为数据存储和绘图工具
Ganglia 通常需要在目标机器上部署 gmond 服务, 并通过配置各种插件从目标机器采集数据; 也可以通过调用 gmetric 命令, 主动上报数据.
Graphite
严格来说, Graphite只干两件事情:
- 时间序列数据存储
- 绘图工具
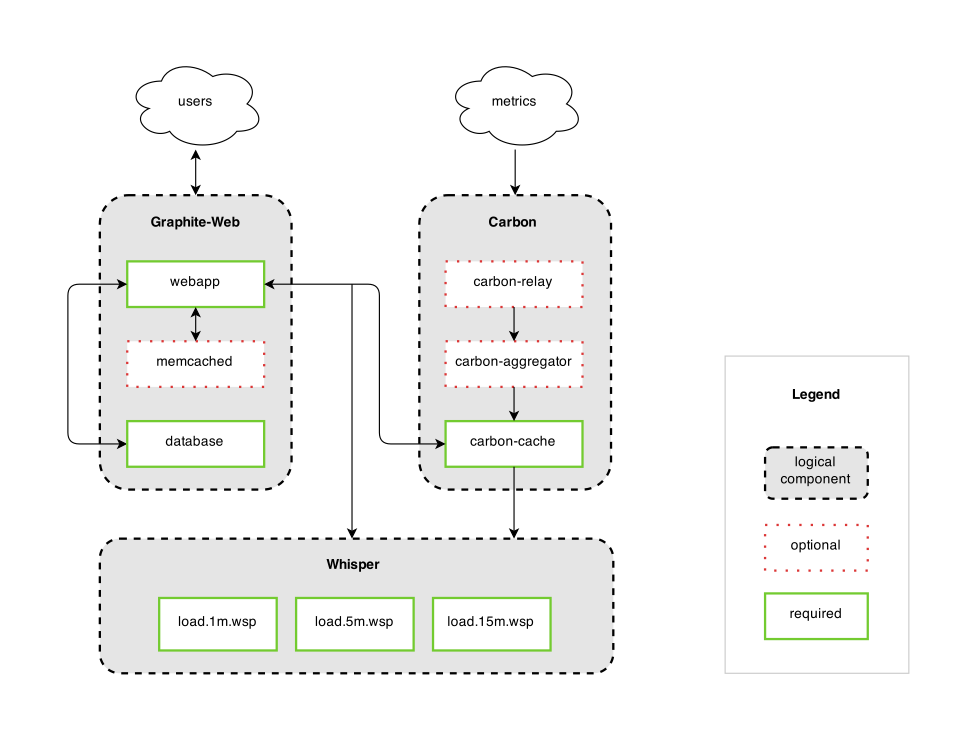
- Graphite-Web 面板, 设计并绘制图表
- Graphite Carbon Daemons 一系列后端存储服务
- carbon-cache
- TCP (或者 UDP) 服务
- 定期通过 whisper 库落地到磁盘
- 尚未落地的数据在内存中缓存, 并可以接受查询请求, 这也是上图中 webapp 和 carbon-cache 交互的地方
- 注意: 不会对数据做聚合处理
- carbon-relay
- 代理服务, 采集服务分发或拷贝给多个 carbon-cache.py 上游
- carbon-aggregator
- 在 carbon-cache.py 之前, 缓存聚合数据
- carbon-cache
- Whisper 存储时间序列数据的存储格式和相关工具, 和 RRD 类似
- Ceres 是计划中替代Whisper的存储格式
数据格式
<key> <numeric value> <timestamp>
标签信息只能在
StatsD
- 通过UDP接收数据
- 支持数据采样放缩(比如说按照1%比率采样, 然后最终统计数据乘以100)
- 数据格式
- 有非常多的backend选择, 不一定和Graphite绑定
- 缺点: 不支持标签格式
- 定时聚合数据并上传给上游
问题: UDP丢包的问题
client 端做采样丢弃, client 端不做聚合, 每次请求都会产生数据, 造成发送的数据量很高.
- https://githubengineering.com/brubeck/
- https://www.digitalocean.com/community/tutorials/an-introduction-to-tracking-statistics-with-graphite-statsd-and-collectd
Elastic 全家桶
- ElasticSearch 数据存储查询服务
- Logstash 插件化的 数据输入, 过滤, 输出服务
- Kibana 面板
- Beats 提供了数据采集方案, 采用Golang开发
- Watcher (之后被整和到 X-Pack 产品中) 提供了告警的功能
作为监控系统来说还是不太适合. 数据采集端比较薄弱. 由于 ElasticSearch 是全文搜索引擎, 对于监控常见的数值聚合查询很差, 数据量大时不行.
InfluxDB
InfluxDB 时间序列存储引擎, 通过 HTTP API 接受数据, 提供类似SQL的查询语法
不满足与仅仅只做存储, 也要做全栈解决方案, TICK栈:
- TeleGraf 插件化的监控数据采集Agent
- InfluxDB 存储
- Chronograf 展示面板
- Kapacitor 监控
此外, 还提供了托管的云服务.
替代 RRD 以及 Graphite
支持多种插件, collectd, opentsdb, graphite 等.
Prometheus
来源于 Google 内部的 Borgmon 监控系统.
InfluxDB vs Prometheus
监控指标数据类型
- Prometheus: 浮点
- InfluxDB: 浮点, 整数, 字符串
数据格式
-
Prometheus:
metric_name{
= [, = ]*} value [timestamp]? e.g.: http_requests_total{method="post",code="200"} 1027 1395066363000 -
InfluxDB:
measurement[,
= ]* = [, = ]+ timestamp e.g.: weather,location=us-midwest temperature=82 1465839830100400200
个人认为InfluxDB的数据解析格式更有表达力, 尤其是在收集多个指标的场景, P需要重复输出多列冗余信息, 而I只用一行就可搞掂.
数据写入
- Prometheus: Pull 模型, 需要指定数据上报的节点, 不能够动态调整, 可以通过 push gateway 转换成 Push 模式
- InfluxDB: Push 模型, 各个数据源主动上报数据
查询语句
- Prometheus: PromQL 自成一套, 学习成本较高
- InfluxDB: InfluxQL 和SQL差不多, 学习成本低
Go Client 支持
- Prometheus: 官方封装过于复杂, 需要提前指定好标签维度, 实际落地不现实.
- InfluxDB: 实现同样七拐八绕
此外, Prometheus对于写入数据时间有限制, 对于有延迟的数据采集场景不太使用.
- https://github.com/prometheus/pushgateway#about-timestamps
- https://github.com/prometheus/prometheus/issues/398
总结
虽然 Prometheus 被钦定了, 入了CNCF, 但是从个人口味来说, 更加偏好 InfluxDB. 由于SDK实现复杂, 我们项目中基于InfluxDB自己撸了一遍监控汇总的Client, 并结合服务注册, 提供了Pull方式的数据收集, 简化业务开发.
Grafana
一统天下的前端面板, 支持各种数据源. 比其他的面板高(neng)大(zhuang)上(bi)多了, 具体不多说了.
DataDog 服务
实现原理基于 Graphite + StatsD
数据格式上做了扩展, 支持额外的标签
metric.name:value|type|@sample_rate|#tag1:value,tag2
Reference
- http://blog.outlyer.com/metrics-nagios-graphite-prometheus-influxdb
- https://developers.soundcloud.com/blog/prometheus-monitoring-at-soundcloud
- https://prometheus.io/docs/introduction/comparison/
- https://www.influxdata.com/scaling-graphite-with-go-using-graphite-ng-or-influxdb/
- http://blog.takipi.com/graphite-vs-grafana-build-the-best-monitoring-architecture-for-your-application/
- http://blog.dataman-inc.com/shurenyun-sre-207/
- https://fabxc.org/blog/2017-04-10-writing-a-tsdb/
- https://grafana.com/blog/2016/01/05/logs-and-metrics-and-graphs-oh-my/
- https://www.xaprb.com/blog/2014/03/02/time-series-databases-influxdb/
- https://www.xaprb.com/blog/2014/06/08/time-series-database-requirements/