WIP
背景
目前业务上都在用, 何时应该选择RabbitMQ, 何时应该选择Kafka? RabbitMQ主要是Python的celery无脑引入进来的.
首先: 业务逻辑, 没有性能扩缩/风险隔离场景的, 可以不走队列的, 不要走队列. 会导致不必要的复杂性.
队列
- 事件发布通知
- 不需要返回结果
- 需要返回结果的叫RPC
- 服务模块的边界
Kafka服务架构
装逼之问, Kafka性能为什么如此优秀?
- 基于日志文件, 顺序读写 O(1) vs O(log n)
- 充分利用操作系统的读写内存页缓存
- sendfile, zero-copy, 减少用户态切换, 直接socket缓冲区写文件, 数据零拷贝.
- 批量处理, 组提交, 不需要单个消息确认
概念
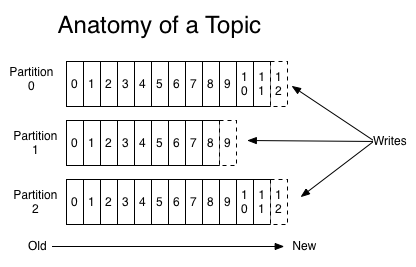
- topic
- partition
- offset
- message
- timestamp
- key
- value
- headers
- broker 节点
- zookeeper
- broker
- topic
- partition
- consumer group instance
- replication
- leader / follower 冗余
- 数据淘汰机制
- 基于时间
- 基于日志大小
写入
- 跟据key决定具体写入partition
- 批量写入
- 写时数据压缩
- 基于分区的写入横向扩展
消费
- 基于offset的手动消费
- Consumer Group / 消费组
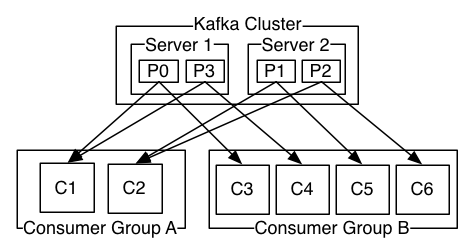
消费组offset管理
__consumer_offsets- log compaction by key
- 消费者缓存定期写回, rebalance时写回
- NOTE: 写回间隔导致的消费监控问题
- 注意消费事务问题
- 保证每条消息至少处理一次, 最好保证消费幂等性
消费延迟计算:
- 基于offset统计: 不同消费速率差别很大, 不能反映真实延迟
- 基于消息时间戳
- 需要写入时配置支持
RabbitMQ简介
AMQP Model

- Publisher
- Exchange
- Routes
- Queue
- Consumer
TODO Exchange的意义 ???
Kafka vs RabbitMQ
Kafka基于磁盘日志的消息代理, pull模式消费数据; RabbitMQ主要基于内存, push模式消费.
生产者/消费者分离, 写入者不用管消费者. 消费堆积不会严重影响Kafka自身服务稳定性. RabbitMQ也有消息持久化, 但是消息堆积严重时容易OOM.
Kafka可随时重放历史数据, RabbitMQ消息一旦确认就不能被再次消费.
Kafka按消息顺序处理, RabbitMQ单个消息处理确认: 顺序性缺点: 单消息处理延迟严重影响整体消费速率. 例子: 视频素材处理. 顺序性好处: 利用消费顺序性+合理分区键值做事务处理保证.
Kafka最大并行数等于分区数限制, RabbitMQ则无限制.
Kafka批处理优化消息处理的吞吐量. RabbitMQ注重单条消息的入队列到完成耗时.
Kafka适合数据量较大的, 面向批处理的场合, 如日志入库等; RabbitMQ则更适合每个消息数据量较小, 需要面向单个消息处理, 每个消息处理耗时不确定的场景.
恰好一次处理 vs 至少处理一次语义.
数据去重
Kafka可以利用日志压缩功能做数据去重, 当作数据存储, 对于数据堆积且只需要处理最近一次消息的场景有用.
RabbitMQ发消息去重一般业务实现还是要依赖一个KV来做.
TODO: 订单确认如何做?
消息层面的数据优先级
RabbitMQ支持消息层面设定优先级.
Kafka严格消息顺序性, 自然不支持. 只能通过不同的topic分开消费隔离.
消费背压
RabbitMQ队列支持淘汰策略, 包括丢弃, 转发等
Kafka的消息队列是异步清理的
Celery vs RabbitMQ
Celery: Python框架, 需要依赖具体Broker及Backend, 一般是RabbitMQ做Broker, Redis做Backend
将结果存到Backend, 实现异步的RPC方式
需要依赖Backend做消息去重
Thoughts: 数据读写接口设计
面向单条消息设计接口, 内部实现通过批量提交优化性能
type Worker interface {
func Handle(...) error
func Flush() error
}