图像基本问题
- classification / 分类问题
- object detection / 目标检测 = 目标框回归问题 + 分类问题
- (instance / semantic / panoptic segmentation) / (实体/语义/全景)分割: 像素级别分类问题
COCO数据集与评价指标
- 90个类 (实际只有80个) + 1 背景类
- 验证集 5K / 训练集 12W
- 多种任务
评价指标
- Intersection over Union (IoU): bbox 框误差 / masks 像素分割误差 ~ Jaccard系数
- 默认 IoU > .5
- Average Precision (AP): 平均
mAP@threshold类比 PR图裙下面积- https://cocodataset.org/#detection-eval
例子
model_name='fasterrcnn_resnet50_fpn' params=41755286 duration='0:09:07
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.36934
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.58546
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.39625
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.21201
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.40316
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.48154
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.30748
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.48482
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.50857
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.31752
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.54431
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.64890
Naive Approach
- 穷举所有的框计算分类 O(W * W * H * H): 框太多, 减少检测框数量
- 每个像素计算分类 O (W * H * C): 没有利用先验信息: 只要框就够了 / 检测物体像素上的连通性
检测框损失及度量
- L1/L2 Distance / 框距离
- 做损失时候一般smooth或者非线性变换一下
- 框尺寸敏感, 需要normalize
- IoU = 相交面积 / 联合面积
- 0 <= IoU <= 1
- IoU = 0: 框不相交
- GIoU = IoU - (闭包面积 - 联合面积) / 闭包面积
- 考虑了不相交情况下的远近
- -1 < GIoU <= 1
- GIoU <=0: 框不相交, 距离越远值越小
Non-maximum Suppression (NMS)
- 输出检测框去重
- 按分类置信度排序, 丢弃过于重合框
- 贪心算法, 会导致精度下降
- Soft NMS 降低重叠框的分类置信度
- Learnable NMS ???
方法
- two-stage detector / 两阶段: 先预测框再对框分类
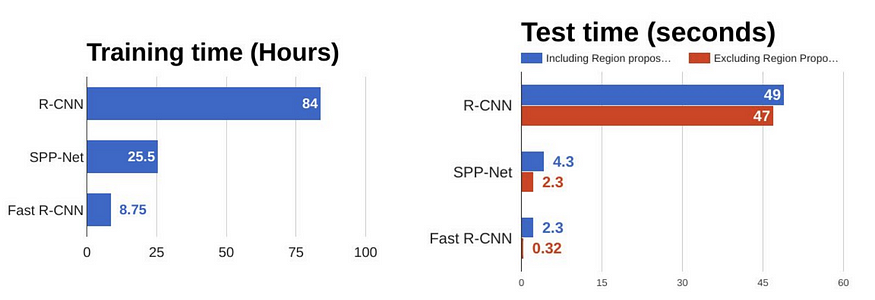
- 2014 RCNN
- 2015 SPP
- 2015 Fast RCNN
- 2015 Faster RCNN
- 2017 FPN
- 2017 Mask RCNN
- one-stage detector / 一阶段: 直接预测框及分类
- 2016 YOLO
- 2016 SSD
- 2017 RetinaNet & Focal Loss
- 2018 YOLOv3
- 2020 DETR
- 2021 Deformable DETR
- 2022 YOLOv7
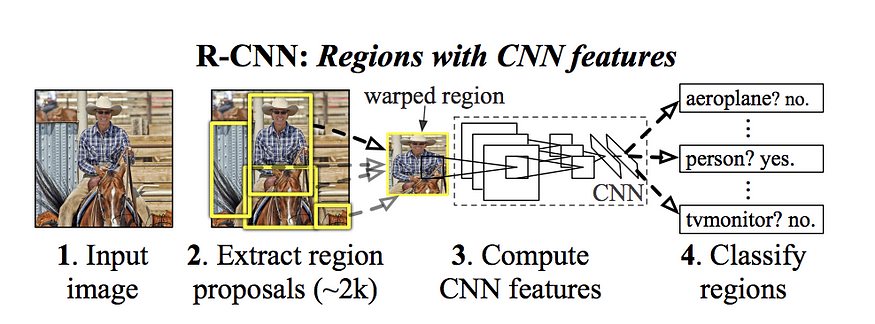
Region CNN (RCNN)
- 提候选框 ~2k
- 缩放成统一尺寸
- CNN 抽特征
- SVM分类器, 回归器修正候选框位置
TODO 传统图像分割算法 / Region Proposal Algorithms
- sliding window search
- (greedy) selective search
Spatial Pyramid Pooling (SPP)
- 传统CNN需要裁剪或者缩放到统一尺寸
- 对任意尺寸图片抽取定长特征


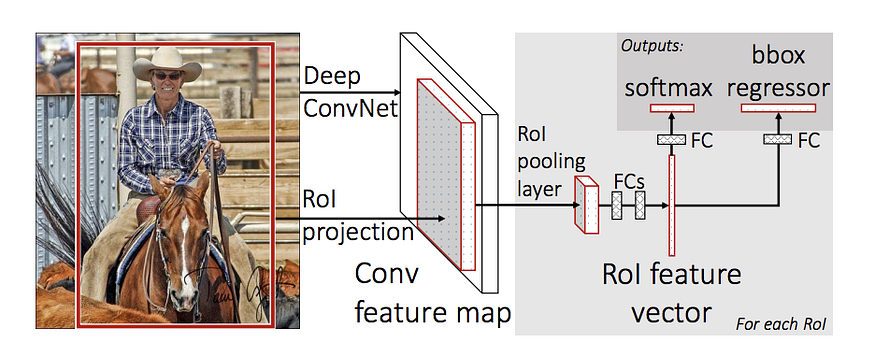
Fast RCNN
- 全图特征过CNN提取特征图 (feature map), 避免候选框特征提取的重复计算
- ROI pooling 层将特征图 (SPP net 简化版)
- FC分类 + FC回归 一起训练
- 相对SPP优化, 可以同时训练CNN和FC层
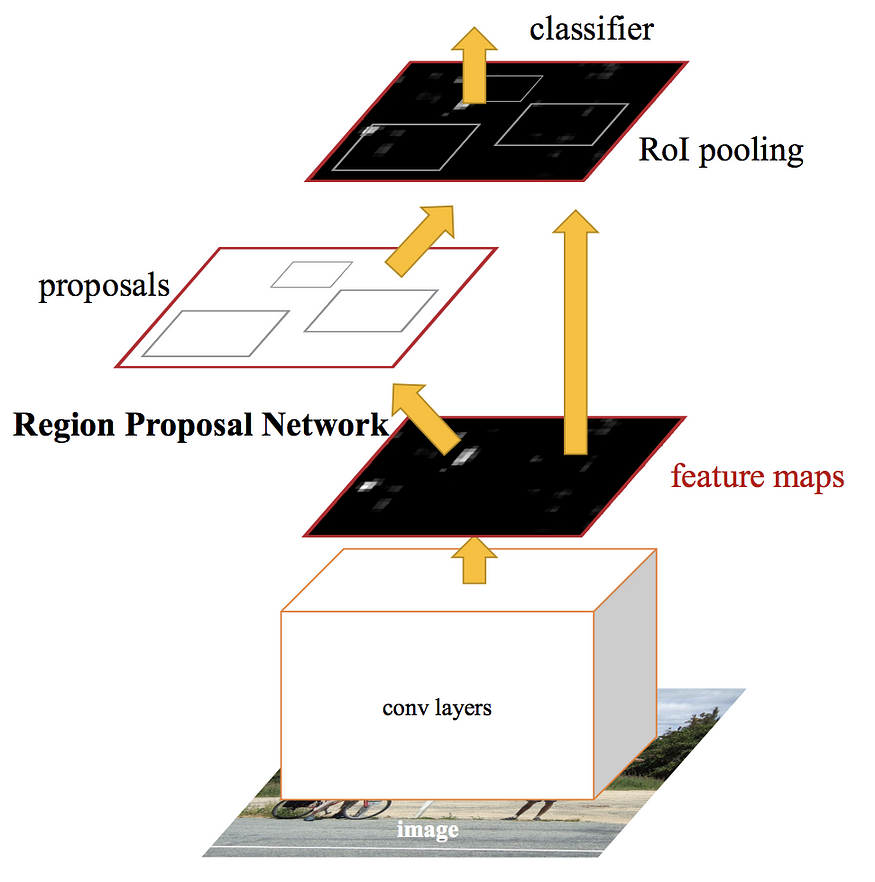
Faster RCNN and Region Proposal Network (RPN)
- 优化特征提取阶段耗时
- RPN 特征提取网络替换候选框提取模块, 从而实现端到端的训练
Mask RCNN 增加了目标分割的FC分类输出训练
Feature Pyramid Networks (FPN)
- CNN多层特征融合, 更好表达图片多维度信息, 优化对于小目标检测
- Bottom-top pathway: 普通多层CNN计算
- Top-bottome pathway: 高层特征影响底层特征计算
- RPN网络的标配

YOLO
- 当作单回归问题
- 图像打网格 (grid)
- 每个网格打锚框 (bounding box / anchor box)
- 对每个锚框 (<100个) 输出分类及目标篇偏移
- 优势: 快, 可实现视频实时监测
- 缺点: 不能检测小物体, 或者尺寸比较奇怪的物体
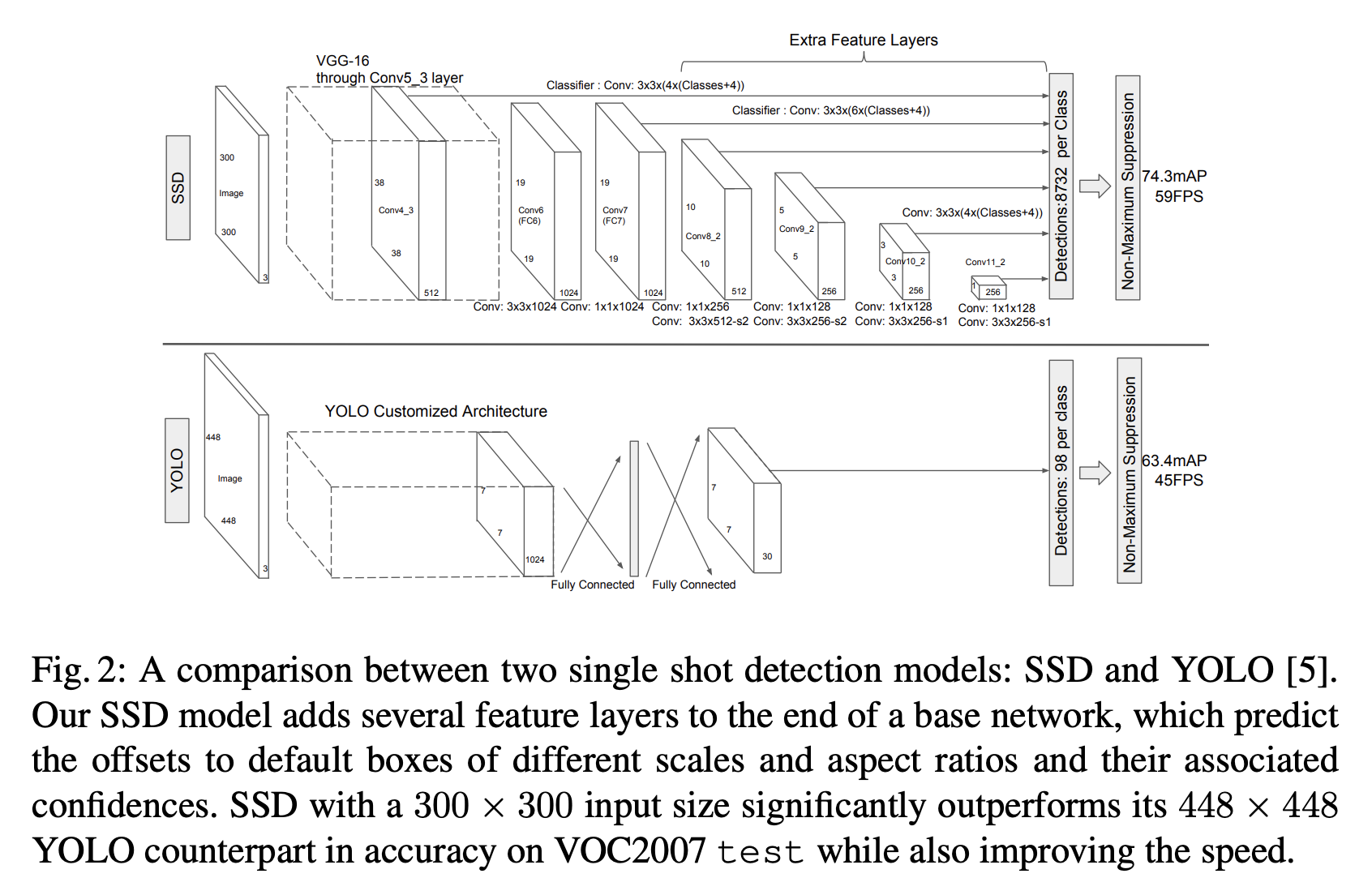
Single Shot Multiscale Detection (SSD)
- 打不同密度的网格
- 预测框会比YOLO多很多 ~ 1W
RetinaNet & Focal Loss
- 均衡密集采样导致分类不均衡问题 (背景分类)
- 交叉熵损失更加关注性能较差的分类

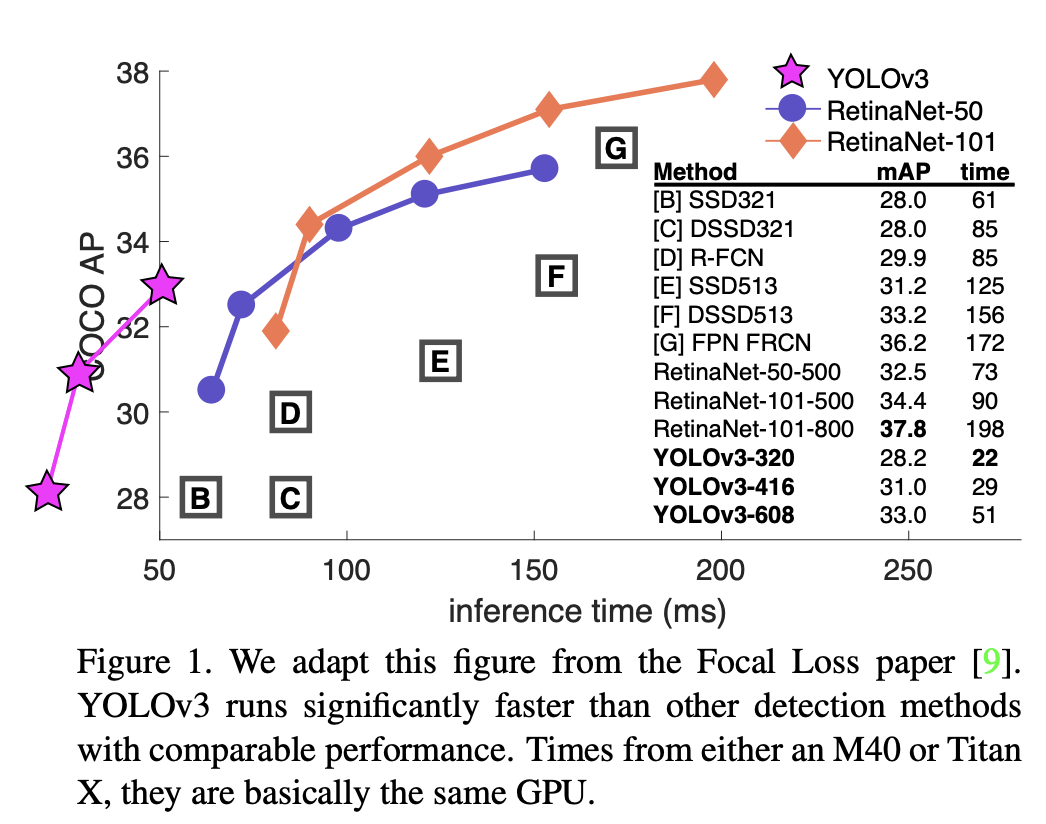
YOLOv3
- 神秘的骨干网络 Darknet-53
- 快! 同样性能情况下, 三倍于SSD的速度
DETR / End-to-End Object Detection with Transformers
- Transformer架构做目标检测
- 100个query当作框
- 直接出框, 不需要后续预测框去重

二分图匹配问题
- https://en.wikipedia.org/wiki/Assignment_problem
- 这里: 检测框属于哪个类, 以最小化分类误差及框回归损失
Deformable DETR
- 引入多尺度特征优化小物体
- 推断比DETR快10倍, 训练收敛快

2022.7 YOLOv7
再次刷榜, 需要关注
模型评价对比
- https://pytorch.org/vision/0.11/models.html#object-detection-instance-segmentation-and-person-keypoint-detection
- https://pytorch.org/vision/0.11/models.html#runtime-characteristics
业务场景
- LOGO检测
- 优化图像分类: 先检测物体再分类
- OCR框检测优化:
- 强化假设, 只检测方框, 或者W/H > r的框, 从而优化文本框检测速度
- 视频OCR框检测